The subject of Failover and Resynchronization is near and dear, as I’ve been configuring mirrored systems for years. I have become quite familiar with how various vendors address this requirement. The principal reason for building a mirrored Picture Archiving and Communication System (PACS) or a mirrored Vendor Neutral Archive (VNA) solution is Business Continuity. Most healthcare organizations realize that they cannot afford to lose the functionality of a mission critical system like a PACS and an Enterprise Archive, so they need more than a Disaster Recovery strategy, they need a functional Business Continuity strategy. Unfortunately, it’s really tough to build a dual-sited, mirrored PACS that actually works. The sync and re-sync process drives most PACS vendors nuts. There are very few PACS that can support multiple Directory databases. I think this shortcoming of most PACS systems is why we have been configuring mirrored VNA solutions from the beginning…if you can’t configure the PACS with a BC solution, then you should at least configure the enterprise archive with a BC solution.

In the dual-sited, mirrored image management system, there are two nearly identical subsystems, often referred to as a Primary and a Secondary. The two subsystems are comprised of an instance of all of the application software components, the required servers, load balancers, and the storage solutions. Ideally these two subsystems are deployed in geographically separate data centers. While it is possible to make both subsystems Active, so half of the organization directs its image data to the Primary subsystem and the other half directs its data to the secondary subsystem, the more common configuration is Active/Passive. In the Active/Passive configuration, the organization directs all of its data to the Primary subsystem and the Primary backs that data up on the Passive Secondary subsystem.
When the Primary subsystem fails or is off-line for any reason, there should be a largely automated “failover” process that shifts all operations from the Primary subsystem to the Secondary subsystem, effectively making it the Active subsystem, until the primary subsystem is brought back on-line. When the Primary subsystem comes back on-line, there should be a largely automated “resynchronization” process that copies all of the data transactions and operational events that occurred during the outage from the Secondary back to the Primary.
Business Continuity operations can be even more complicated in an environment where there is a single instance of the PACS and a dual-sited, mirrored VNA configuration. In this environment, the failover and resynchronization processes can be somewhat complicated, giving rise to numerous questions that should be asked when evaluating either a PACS or a VNA. I thought it would be beneficial to pose a few of those questions and my associated answers.
Q-1: If the hospital-based PACS and Primary VNA are down, how does the administrator access the offsite Secondary VNA and subsequently the data from the offsite VNA? Is the failover automated, or manual? If manual, what exactly does the admin do to initiate the failover?”
A: The response depends very much on the VNA vendor and exactly how that VNA is configured/implemented. Some VNA solutions have poor failover/resynchronization processes. Some look good on paper, but don’t work very well in practice. With some VNA vendors, system failover and resynchronization in a mirrored environment is a real strong suit, as they support many options (VMWare, Load Balanced-automatic, Load Balanced-manual, and Clustering). Some VNA vendors have limited options, which are costly and actually create down time. The better approach is a Load Balanced configuration with automatic failover (which requires certain capabilities existing on the customers network-VLAN/Subnet/Addressing), with manual failover being the second option (and more common). VMWare is becoming much more common among the True VNA vendors, but many of these vendors will still implement the VMWare clients in a load balanced configuration until customers are able to span VMWare across data centers and use VMotion technology to handle the automatic failover. There is also the option of using DNS tricks. For example, IT publishes a hostname for the VNA which translates to an IP in Data Center (DC) A, the DNS has a short Time to Live (TTL), such that if DC A fails, IT can flip the hostname in the DNS and the TTL expires in 1-5 seconds, then all sending devices automatically begin sending/accessing DC B.
There is also a somewhat unique model that implements the mirrored VNA configuration in an Active/Active mode across both Data Centers – whereby the VNA replication technology takes care of sync’ing both DC’s, the application is stateless so it doesn’t matter where the data arrives, because the VNA makes sure both sides get sync’d.
The point in all of this is simply that the better and obviously preferred approach to failover is a near fully automated approach, ONCE THE SYSTEM IS SET-UP. Resynchronization of the data should be automated as well. Only updates/changes to the user preferences might require manual synchronization after a recovery.
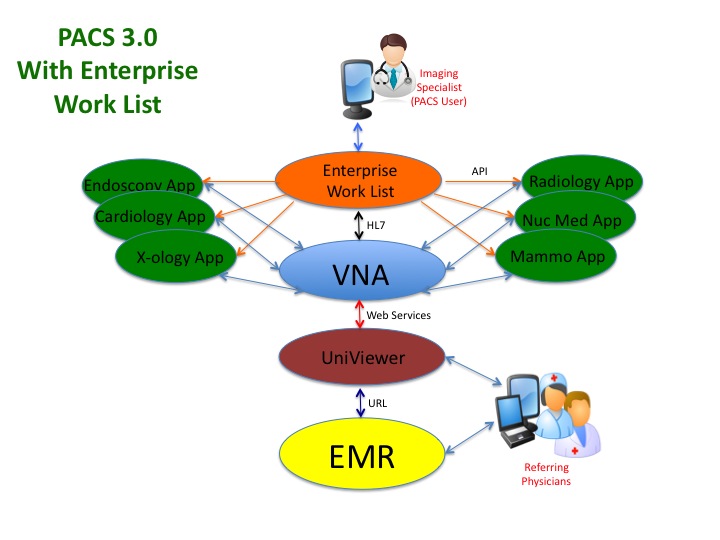
Q-2: What do the UniViewer (zero client, server-side rendering display application) users have to do to access the secondary instance of the UniViewer? Do the users have to know the separate URL to login to that second UniViewer?
A: If implemented correctly, the UniViewer should leverage the same technology as described above for the VNA. The user’s URL call goes to a load balancer, which selects the Active UniViewer rendering server. If the Primary UniViewer (Active) has a failure, another node, or another data center takes over transparent to the end user. The rendering server in turn points to a load balanced VNA such that the users need to do nothing differently if the UniViewer servers or the VNA servers switch.
Q-3: Where do modalities send new studies if the onsite PACS and/or the Primary VNA are down?
A: Once again, this is highly variable, and there are several options. [1] If the designated workflow sends new data to the PACS first and that PACS goes down, then I’d argue that the new data should be sent to the onsite VNA. That means changing the destination IP addresses in the modalities. [2] Vice-versa if the designated workflow sends the new data to the VNA first. Most of the better VNA solutions can configure a small instance of their VNA application in what I refer to as a Facility Image Cache (small server with direct-attached storage). One of these FIC units is placed in each of the major imaging departments/facilities to act as a buffer between the Data Center instance of the VNA and the PACS. [3] In this case, the FIC is the Business Continuity back-up to the PACS.
If both the PACS and the local instance of the VNA are down, the new study data should probably be held in the modality’s on-line storage, for as long as that is possible. The modalities could also forward the data across the WAN to the Secondary VNA in the second data center, but the radiologists would probably find it easier to access and review the new study data from the modality workstations.
Of course all of these back-up scenarios are highly dependent on the UniViewer. In the case of those PACS with thin client workstations, if the PACS system goes down, the workstations are useless. In the case of fat client workstations, most are capable of only limited interactions with a foreign archive. See the next question and answer for additional detail.
Q-4: Do the radiologists read new studies at the modalities and look at priors using the UniViewer whose rendering server is located in the offsite data center?
While that is possible, my recommendation would be to use the UniViewer for both new and relevant priors. Some of the UniViewer technology is already pretty close to full diagnostic functionality, some of the very advanced 3D apps being absent. There are already examples of this use of the UniViewer at a number of VNA sites…not only for teleradiology applications, but also diagnostic review if the PACS system goes down. My prediction is that the better zero client server-side rendering UniViewer solutions are going to be full function diagnostic within a year. This is a critical tipping point in the VNA movement…a real game changer. Once the UniViewer gets to that level of functionality, the only piece of the department PACS that is missing will be the work list manager. As soon as it’s possible to replace a department PACS with a solid [1] VNA, [2] UniViewer, and [3] Work List Manager, the PACS vendors will have a very difficult time arguing that their PACS (less the Archive and Enterprise Viewer) is still worth 90 cents on the dollar, as they are doing today.
Q-5: Does the EMR, if linked to the onsite UniViewer, have a failover process to be redirected to the offsite UniViewer so that clinicians using the EMR still have access to images through the EMR, or do the users need to have the EMR open in one browser and another browser open that points at the offsite UniViewer which they login to separately?
A: Failover from Primary to Secondary UniViewer should be and can be automated (see 1 and 2 above), if implemented correctly and support by the UniViewer technology.
In conclusion, most healthcare organizations are highly vulnerable to the loss of their PACS, because most PACS cannot be configured with a Business Continuity solution. That problem can be remedied with a dual-sited, mirrored Vendor Neutral Archive paired with a dual-sited UniViewer. While most VNA vendors can talk about Business Continuity configurations, their failover and resynchronization processes leave something to be desired. The reader is encouraged to build a set of real-world scenarios, such as those presented here, and use them to discover which VNA will meet their Business Continuity requirements. The Request For Proposal (RFP) document that I have created for VNA evaluations has an entire section on Business Continuity and the underlying functionality.